Grundlagen der Generativen KI: Wie funktionieren Large Language Models (LLMs)?
Large Language Models haben das Feld der künstlichen Intelligenz revolutioniert und treiben alles von Chatbots bis hin zu Content-Erstellungstools an. Aber wie genau funktionieren diese ausgeklügelten Systeme? In diesem umfassenden Leitfaden erkunden wir die Grundlagen der generativen KI und erläutern die komplexen Mechanismen hinter LLMs in verständlichen Begriffen.
Was sind Large Language Models?
Large Language Models sind fortschrittliche KI-Systeme, die darauf ausgelegt sind, menschenähnlichen Text zu verstehen und zu generieren. Diese Modelle werden auf riesigen Datensätzen trainiert, die Milliarden von Wörtern aus Büchern, Artikeln, Websites und anderen Textquellen enthalten. Durch dieses umfangreiche Training lernen LLMs Sprachmuster und können kohärente, kontextuell relevante Antworten auf eine Vielzahl von Eingaben produzieren.
Der Begriff "large" bezieht sich sowohl auf die massiven Datensätze, die für das Training verwendet werden, als auch auf die enorme Anzahl von Parametern (anpassbare Gewichtungen) innerhalb des Modells—oft in den hunderten Milliarden. Diese Größenordnung ist entscheidend für die ausgefeilten Sprachverständnis- und Generierungsfähigkeiten, die wir in modernen KI-Textgenerierungssystemen sehen.
Die Transformer-Architektur: Das Fundament moderner LLMs
Im Herzen der meisten Large Language Models liegt die Transformer-Architektur, die in dem bahnbrechenden 2017er Paper "Attention Is All You Need" vorgestellt wurde. Dieses revolutionäre Design ersetzte frühere sequenzielle Verarbeitungsmethoden durch einen effizienteren parallelen Ansatz.
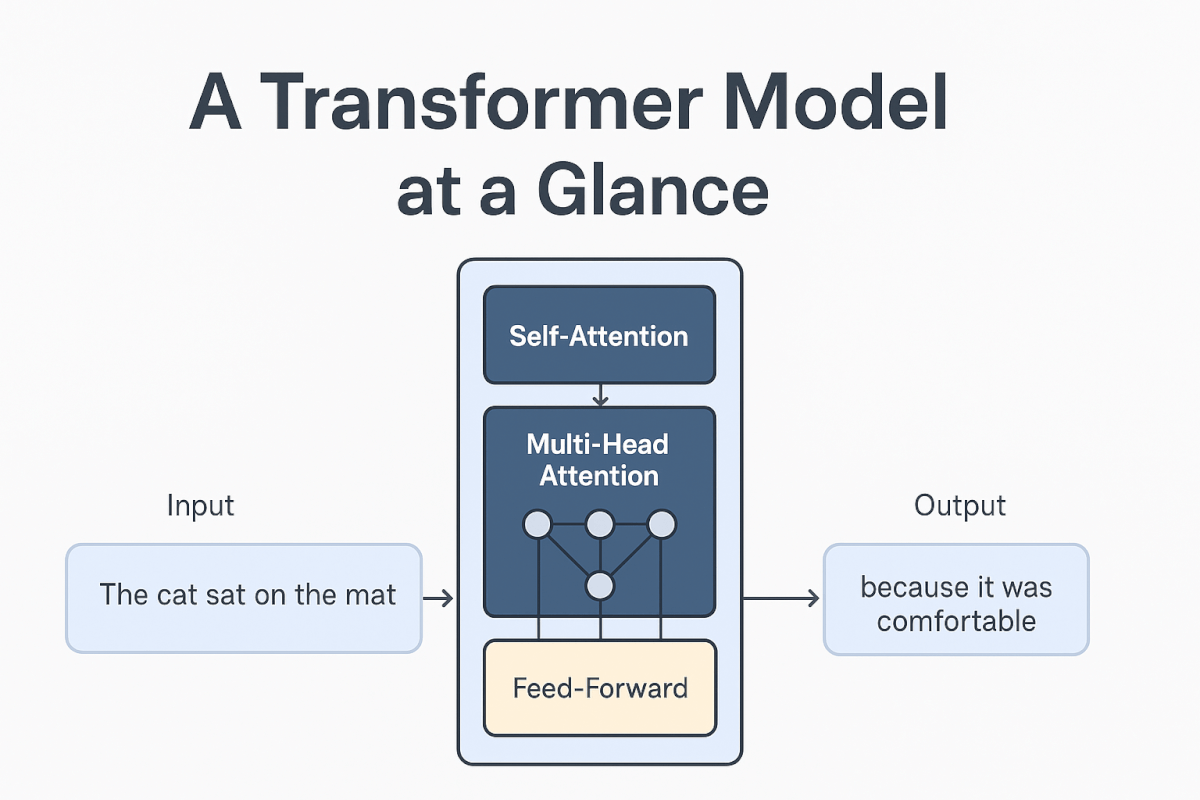
Hauptkomponenten der Transformer-Architektur
Self-Attention-Mechanismus Der Self-Attention-Mechanismus ist vielleicht die wichtigste Innovation in Transformers. Er ermöglicht es dem Modell, die Wichtigkeit verschiedener Wörter in einem Satz zu gewichten, wenn es jedes einzelne Wort verarbeitet. Zum Beispiel hilft der Self-Attention-Mechanismus in dem Satz "Die Katze saß auf der Matte, weil sie bequem war" dem Modell zu verstehen, dass "sie" sich auf "die Matte" und nicht auf "die Katze" bezieht.
Multi-Head Attention Anstatt einen einzigen Attention-Mechanismus zu verwenden, setzen Transformer mehrere Attention-"Köpfe" ein, die sich auf verschiedene Aspekte der Beziehungen zwischen Wörtern konzentrieren. Dies ermöglicht es dem Modell, verschiedene Arten von sprachlichen Mustern gleichzeitig zu erfassen—einige Köpfe könnten sich auf die Syntax konzentrieren, andere auf die Semantik und wieder andere auf weitreichende Abhängigkeiten.
Feed-Forward-Netzwerke Zwischen den Attention-Schichten enthalten Transformer vorwärtsgerichtete neuronale Netzwerke, die die von den Attention-Mechanismen gesammelten Informationen verarbeiten. Diese Netzwerke helfen dabei, die beachteten Informationen in nützlichere Darstellungen für die nächste Schicht zu transformieren.
Layer Normalization und Residual Connections Diese technischen Komponenten helfen dabei, das Training zu stabilisieren und Informationen effektiv durch das tiefe neuronale Netzwerk fließen zu lassen, wodurch das Modell komplexe Muster lernen kann, ohne wichtige Informationen aus früheren Verarbeitungsstufen zu verlieren.
Wie LLM-Training funktioniert
Das Training von Large Language Models ist ein rechenintensiver Prozess, der in mehreren Stufen abläuft, wobei jede Stufe einem spezifischen Zweck bei der Entwicklung der Fähigkeiten des Modells dient.
Pre-Training: Lernen der Sprachgrundlagen
Während des Pre-Trainings lernt das Modell, das nächste Wort in einer Sequenz vorherzusagen, indem es massive Mengen an Textdaten verarbeitet. Diese scheinbar einfache Aufgabe lehrt dem Modell fundamentale Aspekte der Sprache, einschließlich:
- Grammatik- und Syntaxregeln
- Faktenwissen über die Welt
- Logisches Denkvermögen
- Schreibstile und Konventionen
- Beziehungen zwischen Konzepten
Der Pre-Training-Prozess umfasst typischerweise die Verarbeitung von Billionen von Tokens (einzelne Wörter oder Wortteile) unter Verwendung leistungsstarker Computing-Cluster mit Tausenden von spezialisierten Prozessoren. Diese Phase kann Wochen oder Monate dauern und erfordert erhebliche Rechenressourcen.
Fine-Tuning: Spezialisierung für spezifische Aufgaben
Nach dem Pre-Training durchlaufen Modelle oft ein Fine-Tuning, um ihre Leistung für bestimmte Anwendungen zu optimieren. Dieser Prozess beinhaltet das Training des Modells auf kleineren, spezifischeren Datensätzen, die für den beabsichtigten Anwendungsfall relevant sind. Zum Beispiel könnte ein Modell auf medizinischer Literatur fine-getunt werden, um seine Leistung in Gesundheitsanwendungen zu verbessern.
Reinforcement Learning from Human Feedback (RLHF)
Viele moderne LLMs integrieren eine zusätzliche Trainingsphase namens Reinforcement Learning from Human Feedback. In diesem Prozess bewerten menschliche Evaluatoren verschiedene Modellausgaben, und das Modell lernt, Antworten zu produzieren, die besser mit menschlichen Präferenzen für Hilfsbereitschaft, Genauigkeit und Sicherheit übereinstimmen.
Vielfältige Anwendungsfälle für Large Language Models
Die Vielseitigkeit von LLMs hat zu ihrer Adoption in zahlreichen Branchen und Anwendungen geführt und demonstriert das breite Potenzial der generativen KI-Technologie.
Content-Erstellung und Schreiben
LLMs zeichnen sich in verschiedenen Formen der KI-Textgenerierung aus, einschließlich:
- Artikel schreiben: Erstellung von Blog-Posts, Nachrichtenartikeln und Marketing-Texten
- Kreatives Schreiben: Generierung von Geschichten, Gedichten und Skripten
- Technische Dokumentation: Erstellung von Benutzerhandbüchern, API-Dokumentation und Tutorials
- E-Mail und Kommunikation: Verfassen professioneller Korrespondenz und Social Media-Posts
Code-Generierung und Programmierassistenz
Moderne LLMs haben bemerkenswerte Fähigkeiten beim Verstehen und Generieren von Code in mehreren Programmiersprachen gezeigt. Sie können:
- Vollständige Funktionen und Programme basierend auf natürlichsprachlichen Beschreibungen schreiben
- Bestehenden Code debuggen und Verbesserungen vorschlagen
- Komplexe Programmierkonzepte in verständlichen Begriffen erklären
- Code zwischen verschiedenen Programmiersprachen übersetzen
Bildungs- und Trainingsanwendungen
In Bildungsumgebungen dienen LLMs als leistungsstarke Lernwerkzeuge durch:
- Bereitstellung personalisierter Nachhilfe und Erklärungen
- Erstellung von Übungen und Quizzes
- Anbieten von Schreibfeedback und -vorschlägen
- Erleichterung des Sprachenlernens durch Gesprächspraxis
- Kundenservice und Support
Viele Organisationen setzen LLMs ein, um ihre Kundenservice-Operationen zu verbessern durch:
- Automatisierte Chatbots, die Routineanfragen bearbeiten
- E-Mail-Antwortgenerierung für Support-Tickets
- Erstellung und Pflege von Wissensdatenbanken
- Mehrsprachige Kundenbetreuung
Forschung und Analyse
Forscher in verschiedenen Bereichen nutzen LLMs für:
- Literaturrecherchen und Forschungszusammenfassungen
- Datenanalyse und Interpretationsunterstützung
- Hypothesengenerierung und Formulierung von Forschungsfragen
- Unterstützung beim Schreiben von Förderanträgen und Papieren
Die Zukunft der Large Language Models
Während sich die generative KI weiterentwickelt, können wir mehrere aufregende Entwicklungen im LLM-Bereich erwarten:
Verbesserte Effizienz: Forscher entwickeln effizientere Architekturen und Trainingsmethoden, die weniger Rechenleistung erfordern und gleichzeitig die Leistung aufrechterhalten oder verbessern.
Multimodale Fähigkeiten: Zukünftige Modelle werden wahrscheinlich Text-, Bild-, Audio- und Videoverarbeitungsfähigkeiten integrieren, was umfassendere KI-Anwendungen ermöglicht.
Spezialisierte Modelle: Wir werden mehr domänenspezifische LLMs sehen, die für bestimmte Branchen oder Anwendungsfälle optimiert sind und überlegene Leistung in spezialisierten Kontexten bieten.
Besseres Reasoning: Laufende Forschung konzentriert sich auf die Verbesserung der logischen Denk- und Problemlösungsfähigkeiten, wodurch LLMs für komplexe analytische Aufgaben zuverlässiger werden.
Die Grenzen verstehen
Obwohl Large Language Models bedeutende technologische Errungenschaften darstellen, ist es wichtig, ihre aktuellen Grenzen zu verstehen:
- Wissensstichtage: Modelle werden auf Daten bis zu einem bestimmten Zeitpunkt trainiert und haben möglicherweise keine Informationen über aktuelle Ereignisse
- Halluzination: LLMs können manchmal überzeugende, aber sachlich falsche Informationen generieren
- Bias: Modelle können Verzerrungen reflektieren, die in ihren Trainingsdaten vorhanden sind
- Kontextgrenzen: Die meisten Modelle haben Grenzen, wie viel Text sie auf einmal verarbeiten können
Fazit
Large Language Models stellen einen der bedeutendsten Fortschritte in der künstlichen Intelligenz dar und transformieren, wie wir mit Technologie für textbezogene Aufgaben interagieren und sie nutzen. Durch das Verstehen der Transformer-Architektur, Trainingsprozesse und vielfältigen Anwendungen von LLMs gewinnen wir Einblick sowohl in die aktuellen Fähigkeiten als auch in das zukünftige Potenzial der generativen KI.
Da sich diese Technologien weiterentwickeln, versprechen sie, neue Möglichkeiten in verschiedenen Branchen zu erschließen, von kreativen Unternehmungen bis zur wissenschaftlichen Forschung. Obwohl Herausforderungen bestehen bleiben, bietet die durch die aktuelle LLM-Technologie gelegte Grundlage eine robuste Plattform für die nächste Generation von KI-Innovationen, die die menschliche Produktivität und Kreativität weiter verbessern werden.
Ob Sie ein Geschäftsführer sind, der die KI-Adoption erwägt, ein Entwickler, der sich für das Bauen mit LLMs interessiert, oder einfach nur neugierig darauf sind, wie diese Systeme funktionieren - das Verstehen der Grundlagen von Large Language Models ist entscheidend für die Navigation in unserer zunehmend KI-gesteuerten Welt.
