Large language models have revolutionized the field of artificial intelligence, powering everything from chatbots to content creation tools. But how exactly do these sophisticated systems work? In this comprehensive guide, we'll explore the fundamentals of generative AI and break down the complex mechanisms behind LLMs in accessible terms.
What Are Large Language Models?
Large language models are advanced AI systems designed to understand and generate human-like text. These models are trained on vast datasets containing billions of words from books, articles, websites, and other text sources. Through this extensive training, LLMs learn patterns in language, enabling them to produce coherent, contextually relevant responses to a wide variety of prompts.
The term "large" refers to both the massive datasets used for training and the enormous number of parameters (adjustable weights) within the model—often numbering in the hundreds of billions. This scale is crucial for achieving the sophisticated language understanding and generation capabilities we see in modern AI text generation systems.
The Transformer Architecture: The Foundation of Modern LLMs
At the heart of most large language models lies the Transformer architecture, introduced in the groundbreaking 2017 paper "Attention Is All You Need." This revolutionary design replaced previous sequential processing methods with a more efficient parallel approach.
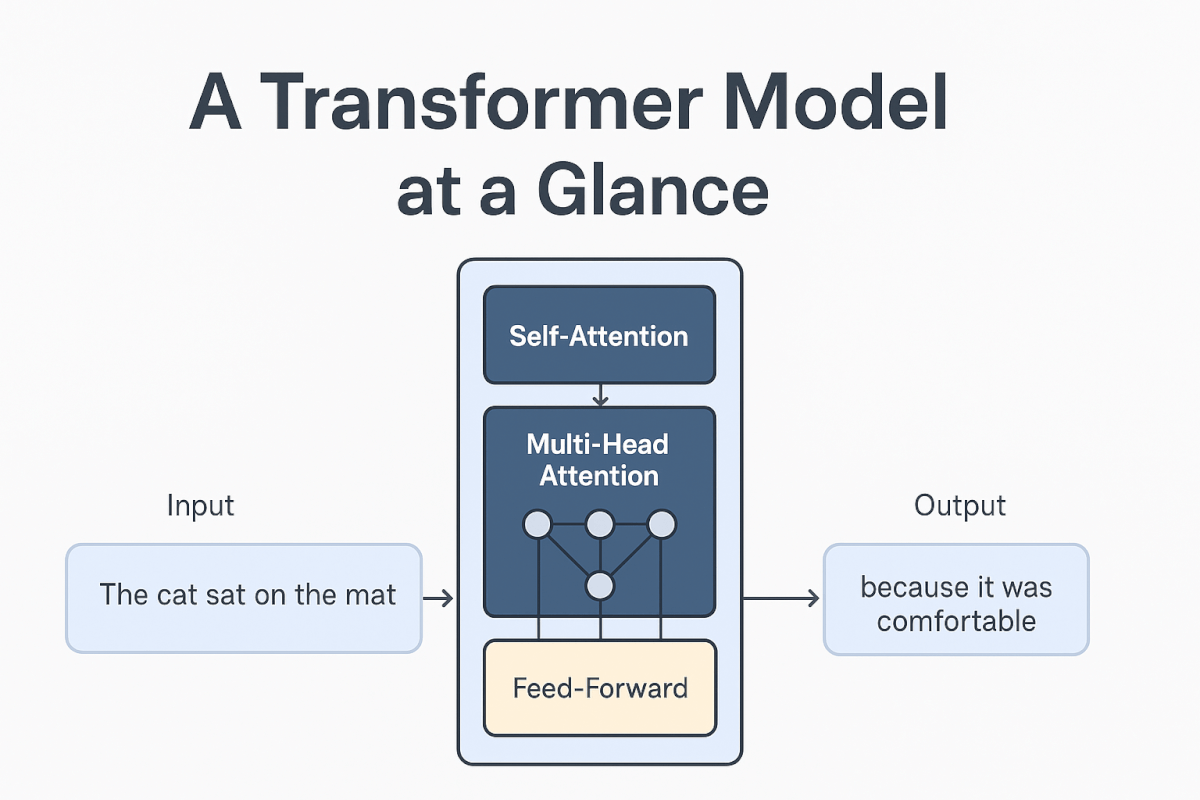
Key Components of Transformer Architecture
Self-Attention Mechanism The self-attention mechanism is perhaps the most crucial innovation in Transformers. It allows the model to weigh the importance of different words in a sentence when processing each individual word. For example, in the sentence "The cat sat on the mat because it was comfortable," the self-attention mechanism helps the model understand that "it" refers to "the mat" rather than "the cat."
Multi-Head Attention Instead of using a single attention mechanism, Transformers employ multiple attention "heads" that focus on different aspects of the relationships between words. This allows the model to capture various types of linguistic patterns simultaneously—some heads might focus on syntax, others on semantics, and still others on long-range dependencies.
Feed-Forward Networks Between attention layers, Transformers include feed-forward neural networks that process the information gathered by the attention mechanisms. These networks help transform the attended information into more useful representations for the next layer.
Layer Normalization and Residual Connections These technical components help stabilize training and allow information to flow effectively through the deep neural network, enabling the model to learn complex patterns without losing important information from earlier processing stages.
How LLM Training Works
Training large language models is a computationally intensive process that occurs in several stages, each serving a specific purpose in developing the model's capabilities.
Pre-training: Learning Language Fundamentals
During pre-training, the model learns to predict the next word in a sequence by processing massive amounts of text data. This seemingly simple task teaches the model fundamental aspects of language, including:
- Grammar and syntax rules
- Factual knowledge about the world
- Common sense reasoning
- Writing styles and conventions
- Relationships between concepts
The pre-training process typically involves processing trillions of tokens (individual words or word pieces) using powerful computing clusters with thousands of specialized processors. This phase can take weeks or months to complete and requires significant computational resources.
Fine-tuning: Specializing for Specific Tasks
After pre-training, models often undergo fine-tuning to optimize their performance for particular applications. This process involves training the model on smaller, more specific datasets relevant to the intended use case. For example, a model might be fine-tuned on medical literature to improve its performance in healthcare applications.
Reinforcement Learning from Human Feedback (RLHF)
Many modern LLMs incorporate an additional training phase called reinforcement learning from human feedback. In this process, human evaluators rank different model outputs, and the model learns to produce responses that align better with human preferences for helpfulness, accuracy, and safety.
Diverse Use Cases for Large Language Models
The versatility of LLMs has led to their adoption across numerous industries and applications, demonstrating the broad potential of generative AI technology.
Content Creation and Writing
LLMs excel at various forms of ai text generation, including:
- Article writing: Creating blog posts, news articles, and marketing copy
- Creative writing: Generating stories, poems, and scripts
- Technical documentation: Producing user manuals, API documentation, and tutorials
- Email and communication: Drafting professional correspondence and social media posts
Code Generation and Programming Assistance
Modern LLMs have shown remarkable capabilities in understanding and generating code across multiple programming languages. They can:
- Write complete functions and programs based on natural language descriptions
- Debug existing code and suggest improvements
- Explain complex programming concepts in accessible terms
- Translate code between different programming languages
Educational and Training Applications
In educational settings, LLMs serve as powerful learning tools by:
- Providing personalized tutoring and explanations
- Creating practice exercises and quizzes
- Offering writing feedback and suggestions
- Facilitating language learning through conversation practice
- Customer Service and Support
Many organizations deploy LLMs to enhance customer service operations through:
- Automated chatbots that handle routine inquiries
- Email response generation for support tickets
- Knowledge base creation and maintenance
- Multi-language customer support capabilities
Research and Analysis
Researchers across various fields leverage LLMs for:
- Literature reviews and research summaries
- Data analysis and interpretation assistance
- Hypothesis generation and research question formulation
- Grant proposal and paper writing support
The Future of Large Language Models
As generative AI continues to evolve, we can expect to see several exciting developments in the LLM space:
Improved Efficiency: Researchers are developing more efficient architectures and training methods that require less computational power while maintaining or improving performance.
Multimodal Capabilities: Future models will likely integrate text, images, audio, and video processing capabilities, enabling more comprehensive AI applications.
Specialized Models: We'll see more domain-specific LLMs optimized for particular industries or use cases, offering superior performance in specialized contexts.
Better Reasoning: Ongoing research focuses on enhancing logical reasoning and problem-solving capabilities, making LLMs more reliable for complex analytical tasks.
Understanding the Limitations
While large language models represent significant technological achievements, it's important to understand their current limitations:
- Knowledge cutoffs: Models are trained on data up to a specific point in time and may lack information about recent events
- Hallucination: LLMs can sometimes generate convincing but factually incorrect information
- Bias: Models may reflect biases present in their training data
- Context limitations: Most models have limits on how much text they can process at once
Conclusion
Large language models represent one of the most significant advances in artificial intelligence, transforming how we interact with and leverage technology for text-related tasks. By understanding the Transformer architecture, training processes, and diverse applications of LLMs, we gain insight into both the current capabilities and future potential of generative AI.
As these technologies continue to evolve, they promise to unlock new possibilities across industries, from creative endeavors to scientific research. While challenges remain, the foundation laid by current LLM technology provides a robust platform for the next generation of AI innovations that will further enhance human productivity and creativity.
Whether you're a business leader considering AI adoption, a developer interested in building with LLMs, or simply curious about how these systems work, understanding the basics of large language models is essential for navigating our increasingly AI-powered world.
